Article
고해상도 항공 영상과 딥러닝 알고리즘을 이용한 표본강도에 따른 토지이용 및 토지피복 면적 추정
이용규, 심우담, 이정수
*
Assessing the Impact of Sampling Intensity on Land Use and Land Cover Estimation Using High-Resolution Aerial Images and Deep Learning Algorithms
Yong-Kyu Lee, Woo-Dam Sim, Jung-Soo Lee
*
1Department of Forest management, Kangwon National University, Chuncheon 24341, Korea
© Copyright 2023 Korean Society of Forest Science. This is an Open-Access article distributed under the terms of the
Creative Commons Attribution Non-Commercial License (http://creativecommons.org/licenses/by-nc/4.0/) which permits
unrestricted non-commercial use, distribution, and reproduction in any
medium, provided the original work is properly cited.
Received: Jan 13, 2023; Revised: Apr 10, 2023; Accepted: Apr 11, 2023
Published Online: Sep 30, 2023
요 약
본 연구는 IPCC에서 제시하고 있는 Approach 3 수준의 토지이용 및 토지피복 면적 추정을 위해 고해상도 항공사진에 딥러닝 알고리즘과 Sampling method를 적용하였으며, 표본강도에 따라 토지피복 면적을 산출하고 최적의 표본강도를 도출하는 것을 목적으로 하였다. 원격탐사자료로는 51 cm급의 고해상도 칼라 항공 이미지를 사용하였으며, 딥러닝 알고리즘은 전이 학습이 적용된 VGG16 아키텍처를 활용하였다. 딥러닝 기반 토지피복 분류모델의 학습과 검증은 육안판독을 통해 선별된 데이터를 이용하였다. 최적의 표본강도를 도출하기 위한 평가는 7개의 표본강도(4 × 4 km, 2 × 4 km, 2 × 2 km, 1 × 2 km, 1 × 1 km, 500 × 500 m, 250 × 250 m)에 따른 토지이용 및 토지피복 면적을 추정하고 환경부에서 제시한 토지피복지도와 비교하였다. 본 연구 결과, 딥러닝 기반의 토지피복 분류 모델의 전체정확도와 카파계수는 각각 91.1%와 88.8%였다. F-Score는 초지를 제외한 모든 범주가 90% 이상으로 구축되어 모델의 정확도가 우수하였다. 표본강도 별 적합도 검정은 유의수준 0.1에서 4 × 4 km를 제외한 모든 표본강도에서 환경부에서 제시한 토지피복지도의 면적 비율과 유의한 차이를 보이지 않았다. 또한, 표본강도가 증가할수록 상대표준오차와 상대효율은 감소하였으며, 상대표준오차는 1 × 1 km 표본강도에서 모든 토지피복범주가 15% 이하로 감소하였다. 따라서, 지역 단위의 토지피복 면적 산정을 위해서는 표본강도를 1 × 1 km보다 상세하게 설정하는 것이 적합하다고 판단된다.
Abstract
This research assessed the feasibility of using high-resolution aerial images and deep learning algorithms for estimating the land-use and land-cover areas at the Approach 3 level, as outlined by the Intergovernmental Panel on Climate Change. The results from different sampling densities of high-resolution (51 cm) aerial images were compared with the land-cover map, provided by the Ministry of Environment, and analyzed to estimate the accuracy of the land-use and land-cover areas. Transfer learning was applied to the VGG16 architecture for the deep learning model, and sampling densities of 4 × 4 km, 2 × 4 km, 2 × 2 km, 1 × 2 km, 1 × 1 km, 500 × 500 m, and 250 × 250 m were used for estimating and evaluating the areas. The overall accuracy and kappa coefficient of the deep learning model were 91.1% and 88.8%, respectively. The F-scores, except for the pasture category, were >90% for all categories, indicating superior accuracy of the model. Chi-square tests of the sampling densities showed no significant difference in the area ratios of the land-cover map provided by the Ministry of Environment among all sampling densities except for 4 × 4 km at a significance level of p = 0.1. As the sampling density increased, the standard error and relative efficiency decreased. The relative standard error decreased to ≤15% for all land-cover categories at 1 × 1 km sampling density. These results indicated that a sampling density more detailed than 1 x 1 km is appropriate for estimating land-cover area at the local level.
Keywords: LULUCF; land cover classification; VGG16; transfer learning; sampling method
서 론
국제사회는 2020년 만료되는 교토의정서를 대체하기 위하여 새 기후변화 체제인 파리협정을 채택하였으며, 교토의정서와는 다르게 자발적으로 감축 목표를 설정하는 상향식으로 전환되었다. 또한, 파리 협정의 투명성 법칙에 따르면 각국의 감축 행동을 측정 가능하고(Measurable), 보고 가능하고(Reportable), 검증 가능한(Verifiable) 방식으로 평가하는 MRV 체계가 요구되었다(Yoo and Yoon, 2018). 이러한 국제적인 동향에 맞추어 우리나라는 2030년 온실가스 감축 목표를 18년 배출량 대비 40% 감축 목표를 설정하였으며, 산림·임업·해양 등 흡수원 부문의 흡수량의 목표를 −26.7백만 톤을 목표를 두고 있다. 특히, 산림·임업 분야에서는 산림경영의 지속가능성 증진, 숲가꾸기, 목재활용, 산림 보전·복원 도시숲 가꾸기 등을 통해 감축목표를 달성하고자 한다. 하지만, 우리나라의 산림 면적은 1990년 6,476천 ha에서 2021년 6,294천 ha으로 최근 30년간 지속적으로 줄어드는 추세이며, 이에 따라, 산림 전용 면적에 대한 모니터링을 통해 온실가스 배출량에 대하여 산정할 필요가 있다(Korea Forest Service, 2022).
IPCC 지침에서 제시하고 있는 LULUCF 분야 통계산출 방법은 크게 3가지로 구분되어 있으며, Approach 1에서 Approach 3으로 수준이 올라갈수록 토지이용의 면적변화량과 함께 공간적인 개념이 포함된 토지이용 간의 변화량을 파악할 수 있도록 정의하고 있다(National Institute of Forest Science, 2021; Smith et al., 2014). 하지만, 우리나라 온실가스 인벤토리는 전체 토지이용 및 전용된 면적을 구분하지 못하고 있어 Approach 3 수준의 토지이용변화 모니터링의 적용이 필요하다(Greenhouse Gas Inventory and Research Center, 2021).
Approach 3 수준의 국가 단위의 모니터링을 위해서는 넓은 범위를 한 번에 주기적으로 관측할 수 있는 GIS와 원격탐사 기술의 활용은 필수적이며, 산림변화모니터링 연구에 활용되고 있다. 최근, 원격탐사분야에서는 머신러닝과 딥러닝기술을 적용한 토지피복분류에 관한 연구가 활발하게 진행되고 있으며, 2006년 이후 Random forest, Support vector machine 등 머신러닝 기법과 Alexnet, VGGNet, ResNET 등 딥러닝 기법을 활용한 인공지능 기반의 영상 분류에 관한 연구가 활발히 진행되고 있다(Zhou et al., 2019). IPCC에서는 Approach 3 수준의 LULUCF 분야 온실가스 배출 및 흡수량 산정의 활동자료 구축방법으로 Sampling method과 Wall-to-Wall 방법을 제시하고 있다. Wall-to-Wall 방법은 대상지 면적 전체를 조사하여 면적 변화를 파악하는 방법으로, 토지의 분포면적을 정확하게 산출할 수 있다는 장점이 있지만 많은 비용과 시간이 소요된다는 한계점을 가지고 있다. 한편, Sampling 방법은 전체 모집단에 대한 정보를 표본으로 예측하는 방법으로 국가단위 토지이용 범주별 면적추정과 토지이용변화 모니터링에 비용·효율적인 방법으로 제시되고 있다(Jung et al., 2020). 따라서, 본 연구는 딥러닝과 Sampling method를 기반으로 표본강도에 따라 토지피복 면적을 산출하고 비교·평가하는 것을 목적으로 하였다.
재료 및 방법
1. 연구대상지 및 사용자료
연구대상지는 대한민국 강원도에 위치한 춘천시(위도 37.8°, 경도 127.2°)로 선정하였다. 춘천시의 면적은 국토지리정보원의 연속수치지형도 기준 약 111,598 ha로 대상지 중심에 도심지가 위치하고 있으며, 외곽지역에 산림지가 분포하는 분지 형태의 도시이다. 또한, 춘천시는 도심지 외곽의 농경지와 소양호, 의암호, 춘천호 등 넓은 면적의 호수가 분포함으로써 다양한 토지 피복으로 구성되어 연구대상지로 선정하였다(Kim and Choi, 2012).
본 연구에서 활용한 원격탐사 자료는 국토지리정보원에서 제공하는 정사보정이 적용된 2019년 항공사진을 이용하였다. 항공사진은 공간해상도가 51 cm이며, RGB 3개의 band로 구성된다(Figure 1). 또한, 데이터 구축 및 평가를 위한 참조자료와 표본강도에 따른 추정면적의 비교를 위해 환경부에서 제공하는 2021년 세분류 토지피복지도를 이용하였다. 토지피복지도 작성지침에 따르면, 세분류 토지피복지도는 산림지를 제외한 분류정확도가 95% 이상이 유지되도록 평가를 시행하고 있다. 환경부 토지피복지도의 분류항목은 크게 시가화·건조지역, 농업지역, 산림지역, 초지, 습지, 나지, 수역으로 7개 항목으로 구분되며, 세분류 토지피복지도는 41개 항목으로 세분화되어 구분되고 있다.
2. 연구방법
본 연구는 세분류 토지피복지도를 참조자료로 활용하여 육안판독을 통해 IPCC 기준에 따라 총 5,000장의 항공사진 데이터세트를 구축하였다. 토지피복분류를 위한 딥러닝 모델은 VGG16을 이용하였으며, 효율적이고 정확도가 높은 모델을 구축하기 위해 전이학습(Transfer learning)을 진행하였다. 구축된 토지피복분류 모델은 표본강도에 따라 구축한 S1(4 × 4 km), S2(2 × 4 km), S3(2 × 2 km), S4(1 × 2 km), S5(1 × 1 km), S6(500 × 500 m), S7(250 × 250 m) 7종류의 데이터세트에 적용하여 표본강도별 토지피복 면적을 산출하였다. 마지막으로 표본강도에 따라 불확도와 상대효율을 산출하여 통계적 효율성을 비교하였다(Figure 2).
1) 딥러닝 모델 구축을 위한 데이터세트 구축
IPCC는 토지이용 범주를 6가지(산림지, 농경지, 초지, 습지, 정주지, 기타토지)로 구분하고 있다(Intergovernmental Panel on Climate Change, 2019). 본 연구에서는 IPCC 기준과 연구대상지의 특성을 고려하여 토지이용범주를 산림지, 농경지, 초지, 정주지, 기타토지 5개 범주를 설정하여 환경부 세분류 토지피복지도를 5개 범주로 재분류하였다(Park et al., 2019). 세분류 토지피복지도의 목장·양식장(ranch·farm)은 축산과 낙농을 위해 사용하는 시설로써, 부화장·양계장·양돈장 등 생산을 위한 시설물에 대한 항목을 의미한다. 또한, 방목장의 10 × 10 m 이상의 초지는 기타초지로 분류하고 있다. 이에 따라 연구대상지의 목장·양식장은 항공사진을 판독할 때 공장 및 창고의 피복특성과 유사하기 때문에 정주지로 재분류하였다. 과수원(Orchard)은 포도, 복숭아 등 과수를 재배하는 토지로써 목본으로 이루어진 토지이지만, 항공사진은 과수원의 식재열이 뚜렷하게 판독이 가능하여 농경지로 재분류하였다. 내륙 습지(Inland wetlands)는 비산림지역으로 항상 습해 있고 우기에는 물이 고이는 지역을 의미하며, 본 연구대상지에서는 주로 하천이나 호소 수변의 갈대 등의 초본류 식생이 분포하고 있어 초지로 재분류하였다(Table 1).
Table 1.
Reclassification of attribute information in the ministry of environment’s land cover map based on IPCC land use category definitions.
|
Reclassification category |
Category of sub-divided land cover map |
|
Forest land |
∙ Coniferous forest
∙ Broadleaf forest |
∙ Mixed forest |
|
Cropland |
∙ Consolidated paddy
∙ Paddy without consolidation
∙ Consolidated Field
∙ Field without consolidation |
∙ Orchard
∙ Facility plantation
∙ Other plantation |
|
Grassland |
∙ Natural grassland
∙ Golf course |
∙ Inland wetlands
∙ Other grassland |
|
Wetlands |
∙ River |
∙ Lake |
|
Settlements |
∙ Single housing facility
∙ Industrial facilities
∙ Educational administrative facilities
∙ Other public facilities
∙ Other transportation communication facilities
∙ Joint housing facility
∙ Road |
∙ Ranch·Farm
∙ Culture·Sports·Recreation facilities
∙ Commercial business facilities
∙ Railroad
∙ Port
∙ Mixed area
∙ Environmental infrastructure |
Download Excel Table
데이터세트는 선행연구사례를 참고하여 각 분류범주별 1,000장의 이미지를 구축하였다(Yang et al., 2018; Yang et al., 2019). 데이터세트 이미지는 최대 표본강도인 250 × 250 m를 고려하여 이미지가 중첩이 되지 않고, 각 분류범주의 특징이 나타날 수 있도록 1 ha 면적의 그리드를 구축하고 해당 영역의 이미지를 추출하였다. 딥러닝모델의 학습을 위해서는 데이터 레이블링 과정이 필수적으로 요구되며, 세분류 토지피복지도를 참조자료로 육안판독을 통해 데이터세트를 구축하였다. 데이터세트의 구축은 100 × 100 m 그리드 구축 및 이미지 추출, 그리드 내의 범주별 면적 산출, 하나의 토지피복 범주 면적 비율이 80% 이상인 그리드 추출, 무작위 이미지 선정, 육안판독을 통한 최종 데이터세트 선정 순으로 수행되었다(Figure 3). 마지막으로, 학습데이터와 검증데이터는 무작위추출 방법을 이용하여 구축된 데이터세트를 7:3 비율(학습데이터 3,500장, 검증데이터 1,500장)로 구분하였다(Huang et al., 2021).
Figure 3.
The examples of datasets by land cover categories derived from the aerial photographs.
Download Original Figure
2) 딥러닝 기반 토지피복분류 모델 구축을 위한 VGG16 모델의 학습 및 검증
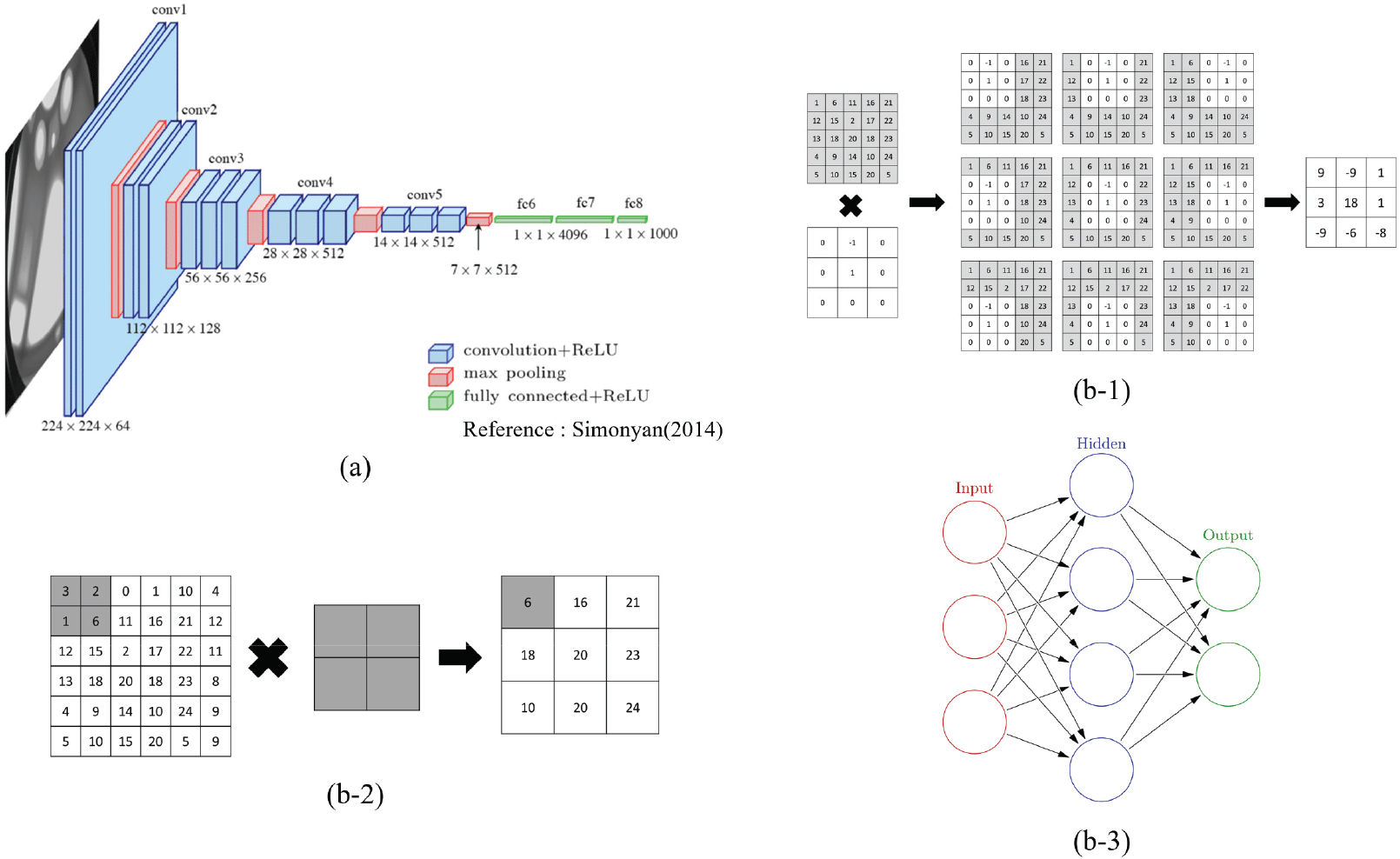
딥러닝을 이용한 이미지 분석은 크게 영상분류(image classification), 객체탐지(object detection), 영상분할(image segmentation)로 구분된다. 영상분류는 하나의 이미지가 어떤 이미지에 해당하는지 분류하는 분석이며, 객체탐지는 이미지 내에서 관심 있는 객체의 영역을 찾아내는 분석, 영상분할은 영상 내에 여러 가지 범주에 대해 분할하고, 분류하는 분석방법이다(Kim et al., 2022). 따라서, 본 연구에서는 Sampling method에 적합한 영상분류 모델 중 가장 널리 사용되고 있는 VGG16 모델을 사용하였다(Muhammad et al., 2018). 현재, VGG16 모델은 의료이미지, 네트워크, 환경 등 다양한 연구 분야에서 활발하게 활용되고 있다(Simonyan and Zisserman, 2014). VGG16모델은 CNN의 기본 아키텍처 Convolution layer, Pooling layer, Fully connected layer로 구성되어 모델을 이해하고 적용하기 용이한 장점이 있다. CNN의 Convolution layer는 필터링을 통해 이미지에 대한 특징맵을 추출하는 과정이며, Convolution layer에서의 학습은 이미지의 특징을 추출할 수 있는 필터의 값을 최적화하는 과정으로 볼 수 있다. Pooling layer는 Convolution layer를 통해 추출된 이미지의 특징맵을 다운샘플링하는 과정이며, 일반적으로 Max pooling을 통해 한 영역 내의 최댓값의 특징을 대푯값으로 설정한다. Pooling layer는 이미지의 크기를 줄임으로써 계산량을 감소시키고, 학습시킬 파라미터를 감소시킴으로써 과적합을 억제할 수 있다. Fully connected layer는 Convolution layer와 Pooling layer의 반복을 통해 추출된 특징들이 평탄화되고 신경망층에 입력되어 실제로 분류가 수행되는 부분이다(Figure 4). 모델의 학습에 적용한 전이학습은 사전에 다른 데이터세트를 활용하여 미리 학습된 모델을 활용하며, 신규 데이터세트를 이용하여 추가로 학습한 딥러닝 모델을 활용하는 것을 의미한다. 전이학습은 딥러닝 모델이 사전에 학습한 데이터세트로부터 다양한 이미지에서 보편적인 특징을 학습했기 때문에, 많은 양의 학습자료 없이도 빠르고 정확한 정확도를 달성할 수 있다는 장점이 있다(Abdalla et al., 2019; Cui et al., 2020). 딥러닝 모델은 파이썬 언어 기반의 딥러닝 구현 라이브러리인 PyTorch를 이용하여 모델을 구축하였으며, 모델 학습에 사용한 하이퍼파라미터는 선행연구를 참조하여 설정하였다. Optimizer와 loss function은 일반적으로 분류 문제에서 많이 활용되고 있는 Adam과 Cross entropy를 이용하였으며, batch size는 데이터의 크기와 컴퓨팅 성능을 고려하여 32로 설정하였다. Learning rate는 전이학습 방법을 이용하기 때문에, 미세조정을 진행하기 위해 일반적으로 사용되는 범위보다 낮은 0.0001으로 설정하였다(Hamedianfar et al., 2022; Rakshit et al., 2018; Naushad et al., 2021). 또한, 구축한 데이터세트는 PyTorch의 transforms 기능을 이용하여 정규화 및 224 pixel × 224 pixel 크기로 리샘플링 되었다. 학습 횟수는 최대 100회로 설정하였으며, 과적합 방지 및 효율적인 모델 학습을 위해 조기 종료(Early stopping) 알고리즘을 적용하여 10회의 학습 동안 모델의 성능이 개선되지 않을 때 학습을 중지하였다(Naushad et al., 2021).
Figure 4.
The architecture of VGG16 model(Simonyan, 2014). (a) Architecture of VGG16; (b) Operation Process of CNN layer; (b-1) Convolution; (b-2) Max pooling; (b-3) Fully connected.
Download Original Figure
3) 딥러닝 기반 토지피복분류 모델의 정확도 평가
딥러닝 모델의 정확도 평가는 딥러닝 기반 토지피복분류 모델의 분류결과와 검증데이터의 라벨 자료를 이용하여 혼동행렬을 작성하였다. 혼동행렬을 기반으로 전체정확도(Overall accuracy; OA), 생산자정확도(Producer’s accuracy; PA), 사용자정확도(User’s accuracy; UA), F-score와 카파계수(kappa)를 산출하였다(Ramadhani et al., 2020; Kiala et al., 2019). 전체정확도는 모든 이미지 개수 중에서 정확하게 분류한 이미지의 비율을 의미하여 계산이 간편하고, 쉽게 이해할 수 있는 장점이 있다. 생산자 정확도는 실제 참값 중 정확하게 분류한 비율을 의미하고 사용자 정확도는 해당 범주의 분류결과 중 정확하게 분류한 비율을 의미한다. 카파계수는 분류결과와 참조자료 간의 우연에 의한 일치율을 제거하고 계산된 통계값으로 원격탐사 분야에서 많이 사용되고 있다(Table 2)(Landis and Koch, 1977; Um, 2013).
Table 2.
Evaluation of land cover classification model using a confusion matrix.
|
Class |
Validation data |
|
A |
B |
C |
∑ |
UA(%) |
|
Classified by deep learning model |
A |
NAA
|
NAB
|
NAC
|
∑AR |
NAA/∑AR × 100% |
|
B |
NBA
|
NBB
|
NBC
|
∑BR |
NBB/∑BR × 100% |
|
C |
NCA
|
NCB
|
NCC
|
∑CR |
NCC/∑CR × 100% |
|
∑ |
∑PA
|
∑PB |
∑PC |
N |
|
|
PA(%) |
NAA/∑PA×100% |
NBB/∑PB×100% |
NCC/∑PC×100% |
|
|
Download Excel Table
4) 표본강도에 따른 토지피복 면적 산출 및 토지피복지도와의 정합성 평가
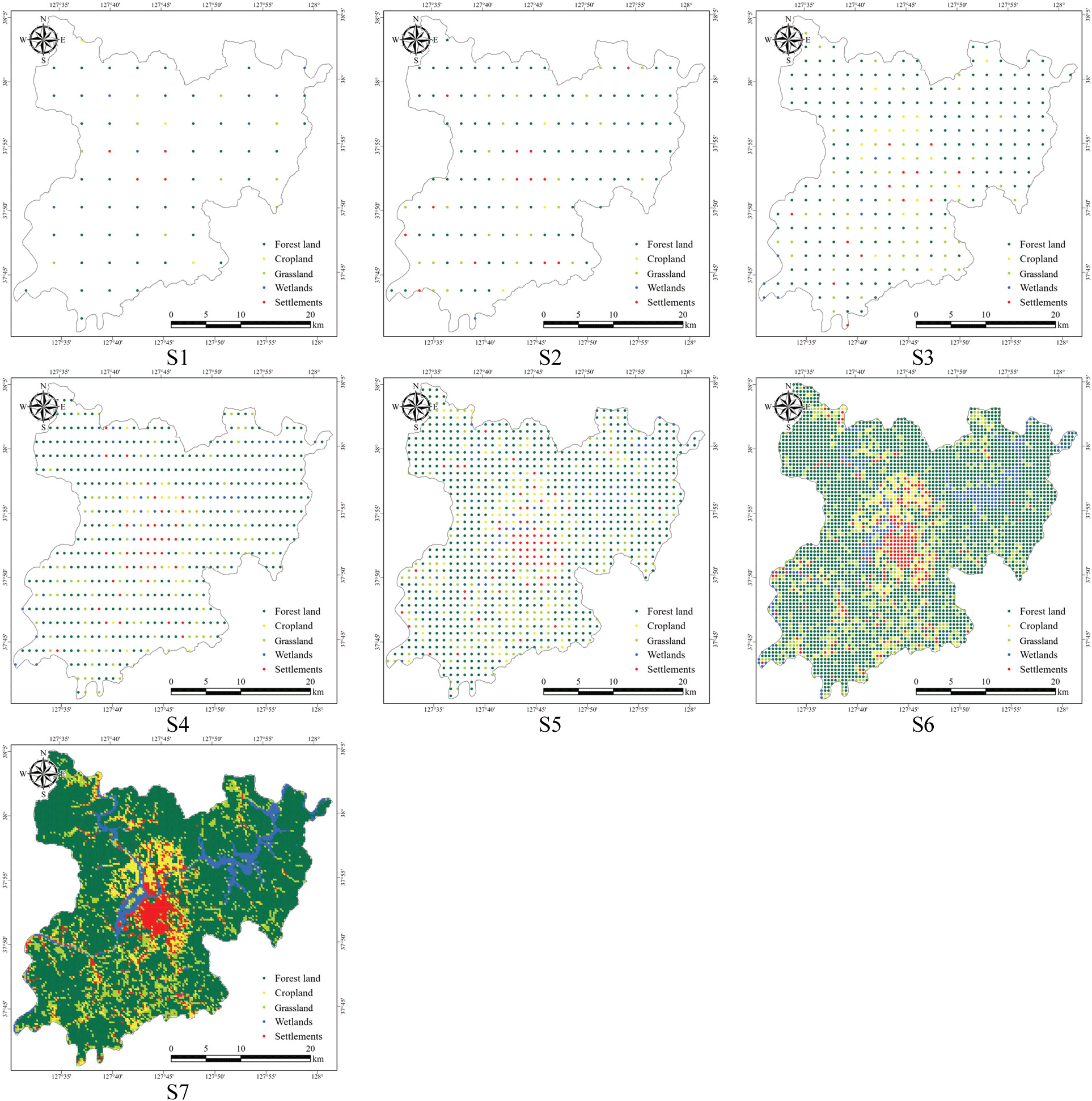
국가산림자원조사의 표본조사는 전국을 대상으로 4 km × 4 km의 일정한 간격으로 계통추출법을 적용하여 표본점을 배치하고 있으며, 도서지방 및 광역시의 경우 2 km 또는 1 km 간격의 보조표본점을 추가 배치할 수 있다(Korea Forest Service, 2021). 또한, Yim et al.(2020)은 샘플링 강도에 따른 전국에 대한 토지이용변화 매트릭스의 비교를 위해 2 × 2 km에서 8 × 8 km까지 7개의 표본강도를 설정하였다. 따라서 본 연구의 대상지가 시군구 단위인 점을 고려하여 250 × 250 m부터 4 × 4 km까지 7개의 표본강도를 설정하였다. 딥러닝 적용을 위한 이미지 데이터는 각 표본강도 S1(4 × 4 km), S2(2 × 4 km), S3(2 × 2 km), S4(1 × 2 km), S5(1 × 1 km), S6(500 × 500 m), S7(250 × 250 m)에 따라 포인트 정보를 구축하고, 해당 포인트를 중심으로 100 × 100 m 크기로 구축하였다. 각 표본강도에 따라 구축된 이미지는 구축된 딥러닝 기반의 토지피복 분류 모델을 이용하여 토지피복 범주 별로 분류되었으며, 분류 결과를 기반으로 표본강도에 따른 토지피복 비율을 도출하였다(Figure 5). 또한, 이미지와 해당 포인트 위치의 재분류된 세분류 토지피복지도의 항목을 이용하여 혼동행렬을 작성하여 OA, PA, UA, kappa를 산출하였다.
Figure 5.
The procedure for applying a deep learning model for estimating land cover area according to sampling method.
Download Original Figure
5) 표본강도에 따른 추정 면적의 통계적 검증
IPCC(2003)에 따르면 sampling method을 이용하여 면적 추정 시, 불확실성을 측정하는 지표로 상대표준오차(Relative Standard Error; RSE)를 제시하고 있다. 상대표준오차는 추정면적의 표준오차에 의해 추정치를 신뢰할 수 있는 확률을 의미하여 표본강도 및 토지피복범주별 상대표준오차를 산출하였다(식 1, 2)(Park et al., 2019).
Ah : Estimated area of Class h
ph : The proportion of samples in Class h for sampling intensity.
상대효율(Relative efficiency; RE)은 두 가지 이상의 추정결과에 대해 분산을 비교하는 방법으로, 본 연구에서는 표본강도에 따른 불확실성을 의미하는 상대표준오차의 분산을 이용하였다. 상대효율의 산출 기준은 중간 표본강도인 S4를 이용하였으며, 상대표준오차의 분산값을 이용하였다. 상대효율을 이용한 평가는 분산이 작아 상대효율 값이 낮게 산출될수록 좋은 추정방법으로 판단한다(식 3) (Moon et al., 2021).
REk : Relative efficiency of sampling intensity k
nS4 and nk : number of samples for sampling intensity S4 and k,
RSES4 and RSEk : RSE of sampling intensity S4 and k.
표본강도에 따라 도출된 토지피복면적의 비율과 토지피복지도의 토지피복면적의 비율이 얼마나 유사한지 검정하기 위해 적합도 검정을 실시하였다. 적합도 검정의 기대비율(Expected ratio)은 토지피복지도의 토지피복면적 비율을 이용하였으며, 표본강도에 따른 총 포인트 수와 기대비율을 곱하여 기대빈도(Expected)를 도출하였다. 관찰빈도(Observed)는 표본강도에 따라 딥러닝 토지피복분류 모델을 이용하여 분류된 포인트의 개수로 설정하였다. 적합도 검정에 따라 산출되는 카이제곱 통계량(χ2)은 기대빈도와 관찰빈도가 같을 경우 0으로 산출되며, 값이 작을수록 토지피복지도와 표본강도에 따른 토지피복면적 비율의 차이가 적은 것으로 판단할 수 있다. 산출된 카이제곱 통계량을 이용하여 p-value를 산출하고, 유의수준 0.1에서 통계적인 유의성을 검정하였다(Table 3)(Moon, 2017; Holt et al., 1980; Kavzoglu and Colkesen, 2013).
Table 3.
The Example of calculating the chi-square statistic.
|
Class |
Expected ratio |
Expected (Ej) |
Observed (Oj) |
(Oj – Ej)2
|
(Oj – Ej)2/Ej
|
χ
2
|
|
Forest land |
0.7442 |
101.96 |
104.00 |
4.18 |
0.04 |
2.84 |
|
Cropland |
0.0595 |
8.15 |
7.00 |
1.33 |
0.16 |
|
Grassland |
0.0814 |
11.15 |
14.00 |
8.11 |
0.73 |
|
Wetlands |
0.0574 |
7.86 |
8.00 |
0.02 |
0.00 |
|
Settlements |
0.0575 |
7.88 |
4.00 |
15.04 |
1.91 |
Download Excel Table
결과 및 고찰
1. 범주별 데이터세트를 이용한 딥러닝 모델의 학습 및 검증
딥러닝 모델의 학습 및 검증은 학습횟수 2회에서 학습정확도 0.949, 학습손실 0.146, 검증정확도 0.911, 검증손실 0.275으로 최적의 성능을 보였으며, 이후 학습 10회 동안 검증손실의 개선이 이루어지지 않아 학습을 종료하였다. 전이학습 방법을 이용한 토지피복분류 연구에서는 학습횟수를 500회, 3,000회 등으로 설정하여 모델을 학습하였으며, 조기종료를 적용한 연구에서는 모델을 21회 학습하였다(Jo et al., 2019; Song et al., 2019; Naushad et al., 2021). 반면, 본 연구에서 구축된 모델은 조기종료를 적용하여 2회부터 11회까지 정확도의 개선이 이루어지지 않아, 2회 학습한 모델이 최종적으로 선정되었다. 검증데이터의 라벨자료와 딥러닝 기반의 토지피복분류 결과의 전체정확도는 91.1%, 카파계수는 88.8%로 일치도가 매우 높았다(Table 4). 본 연구에서 구축된 모델은 선행연구들에 비해 학습횟수는 작았음에도 불구하고, 높은 정확도를 달성하였다. 이에 따라, 토지피복분류 모델 구축에 전이학습을 이용한다면 효율적으로 모델을 구축할 수 있는 것으로 판단된다. 한편, 본 연구보다 정확도가 높았던 선행연구와 비교하면 본 연구의 데이터세트는 하나의 범주가 80% 이상인 지역으로 선정하여 이미지 내에 타 범주가 혼재된 점과 토지피복분류 항목을 국제기준에 따라 5개 범주로 재분류한 점이 정확도에 영향을 미친 것으로 판단된다(Jo et al., 2019). 또한, Park et al.(2019)은 본 연구에서 사용된 VGG16 모델보다 더 깊은 모델인 Inception-V4와 SENet 아키텍처를 이용하였음에도 흑백영상의 산림항공사진 자료를 이용하여 정확도가 낮게 산출되었다. 따라서, 모델에 정확도는 모델의 구조에도 영향을 받지만 사용한 데이터세트의 구축 방법, 분류범주, 이미지 자료 등에 큰 영향을 받는 것으로 판단된다.
Table 4.
The results of the evaluation of the land cover classification model (VGG16) using validation data.
|
Class |
Validation data |
UA(%) |
|
Forest land |
Cropland |
Grassland |
Wetlands |
Settlements |
Total |
|
Classified by deep learning model |
Forest land |
285 |
2 |
26 |
0 |
0 |
313 |
91 |
|
Cropland |
0 |
268 |
4 |
0 |
8 |
280 |
96 |
|
Grassland |
14 |
25 |
268 |
5 |
42 |
354 |
76 |
|
Wetlands |
1 |
0 |
1 |
295 |
0 |
297 |
99 |
|
Settlements |
0 |
5 |
1 |
0 |
250 |
256 |
98 |
|
Total |
300 |
300 |
300 |
300 |
300 |
1,500 |
|
|
PA(%) |
95 |
89 |
89 |
98 |
83 |
|
|
|
F-score(%) |
93 |
92 |
82 |
99 |
90 |
|
|
Download Excel Table
토지피복분류범주 별 F-score는 습지, 산림지, 농경지, 정주지, 초지 순으로 초지를 제외한 모든 범주의 F-score가 90% 이상으로 산출되었다. 특히, 초지는 82%로 가장 낮게 분포하였으며, 특히 사용자 정확도가 76%로 정확도가 낮았다. 이는 산림지의 미립목지 및 제지, 농경지 중 구획이 일정하게 되지 않고, 경지정리가 안 된 밭의 초본식생, 정주지 중 흙이 노출된 나지 부분에서 오분류가 많이 발생하였으며, 공통적으로 타범주와 혼재된 이미지에서 초지로 오분류하는 사례가 발생하였다. 공통적으로 보면 RGB 3채널만 사용한 데이터의 분광특징량의 한계와 토지피복 항목 간의 분광값의 유사성으로 인하여 오분류된 경우들이 발생하였다. 이러한 오분류를 해결하기 위해서는 다중분광 영상을 추가적으로 활용하고, 토지피복범주에 대한 세부적인 검토가 필요할 것으로 판단된다(Song, 2017; Bergado et al., 2016).
2. 표본강도에 따른 면적 추정 결과
표본강도에 따른 토지피복항목별 추정 면적과 세분류 토지피복지도와 비교한 결과, 표본강도가 가장 높은 S7에서 추정 면적 비율이 유사하였다. 특히, S7은 모든 토지피복 범주에서 토지피복지도와의 면적 비율 차이가 0.2% 미만으로 분포하였다. 특히, 검증데이터를 이용하여 딥러닝 모델을 평가하였을 때, 초지가 과대 추정되고, 정주지가 과소 추정되었으나 실제 표본강도에 따라 추출한 이미지에 적용하였을 때는 표본강도가 증가함에 따라 세분류 토지피복지도와의 면적 비율 차이가 감소하였다. 이는 모집단에 대한 데이터의 수가 많을수록 즉, 표본 강도가 증가할수록 토지피복지도와의 면적 비율 차이가 감소하였으며, 토지피복면적 추정에 있어 표본 강도의 중요성을 확인하였다(Table 5; Figure 6).
Table 5.
The estimated results of Land cover area according to sampling intensity.
|
Sampling intensity |
The number of sample point (ratio:%) |
|
Forest land |
Cropland |
Grassland |
Wetlands |
Settlements |
Total |
|
S1 |
49 (72.1) |
6 (8.8) |
3 (4.4) |
7 (10.3) |
3 (4.4) |
68 (100) |
|
S2 |
104 (75.9) |
7 (5.1) |
14 (10.2) |
8 (5.8) |
4 (2.9) |
137 (100) |
|
S3 |
205 (75.1) |
18 (6.6) |
24 (8.8) |
16 (5.9) |
10 (3.7) |
273 (100) |
|
S4 |
416 (74.7) |
34 (6.1) |
42 (7.5) |
36 (6.5) |
29 (5.2) |
557 (100) |
|
S5 |
813 (73.6) |
64 (5.8) |
103 (9.3) |
58 (5.2) |
67 (6.1) |
1,105 (100) |
|
S6 |
3,340 (74.8) |
259 (5.8) |
352 (7.9) |
260 (5.8) |
257 (5.8) |
4,468 (100) |
|
S7 |
13,029 (74.6) |
1,051 (6.0) |
1,415 (8.1) |
974 (5.6) |
1,005 (5.8) |
17,474 (100) |
Download Excel Table
3. 세분류 토지피복지도와 딥러닝 모델의 토지이용 항목별 불일치 사례 검토
표본강도에 따른 분류결과와 토지피복지도의 혼동행렬을 작성하였을 때는 표본강도가 증가할수록 전체정확도(83.8% → 79.5%)와 카파계수(67.7% → 55.0%)가 감소하였다. 또한, 토지피복범주 별 F-score는 산림지와 습지가 다른 토지피복범주에 비해 약 80~90%로 높았으며 초지는 약 20~40%로 낮았으며, 초지는 습지를 제외한 산림지, 농경지, 정주지 항목과 오분류가 다수 발생하였다. 이러한 오분류는 모델의 정확도 평가에 활용된 혼동행렬의 결과와 유사하였다(Table 6). 표본강도가 증가할수록 전체정확도와 카파계수가 감소하는 것은 토지피복지도와 항공사진의 시계열이 불일치 하는 점과 표본강도가 증가함에 따라 다양한 토지피복 범주가 혼재된 이미지의 입력 비율이 증가한 것이 원인으로 판단된다. 따라서, 딥러닝 모델을 이용한 면적 추정을 개선하기 위해서는 여러 범주가 혼재된 이미지에 대한 필터링 기준과 범주가 혼재된 이미지를 줄이기 위해 이미지 크기에 대한 추가적인 검토가 필요하다.
Table 6.
Assessment of deep learning models with respect to sampling intensity was conducted by comparing them with the Subdivision Land Cover Map. (Unit : %)
|
Sampling intensity |
OA |
Kappa |
F-score |
|
Forest land |
Cropland |
Grassland |
Wetlands |
Settlements |
|
S1 |
83.8 |
67.7 |
93.6 |
66.7 |
30.8 |
92.3 |
57.1 |
|
S2 |
77.4 |
53.5 |
90.6 |
60.0 |
41.0 |
62.5 |
35.3 |
|
S3 |
79.1 |
57.4 |
89.8 |
68.6 |
37.8 |
84.8 |
43.5 |
|
S4 |
78.3 |
55.2 |
89.7 |
60.4 |
32.4 |
92.8 |
41.8 |
|
S5 |
76.7 |
53.3 |
90.1 |
45.5 |
35.1 |
78.3 |
48.5 |
|
S6 |
78.4 |
54.2 |
90.6 |
50.7 |
32.7 |
81.0 |
40.9 |
|
S7 |
79.5 |
55.0 |
91.5 |
48.2 |
31.2 |
81.6 |
44.4 |
Download Excel Table
4. 표본강도에 따른 추정면적의 평가
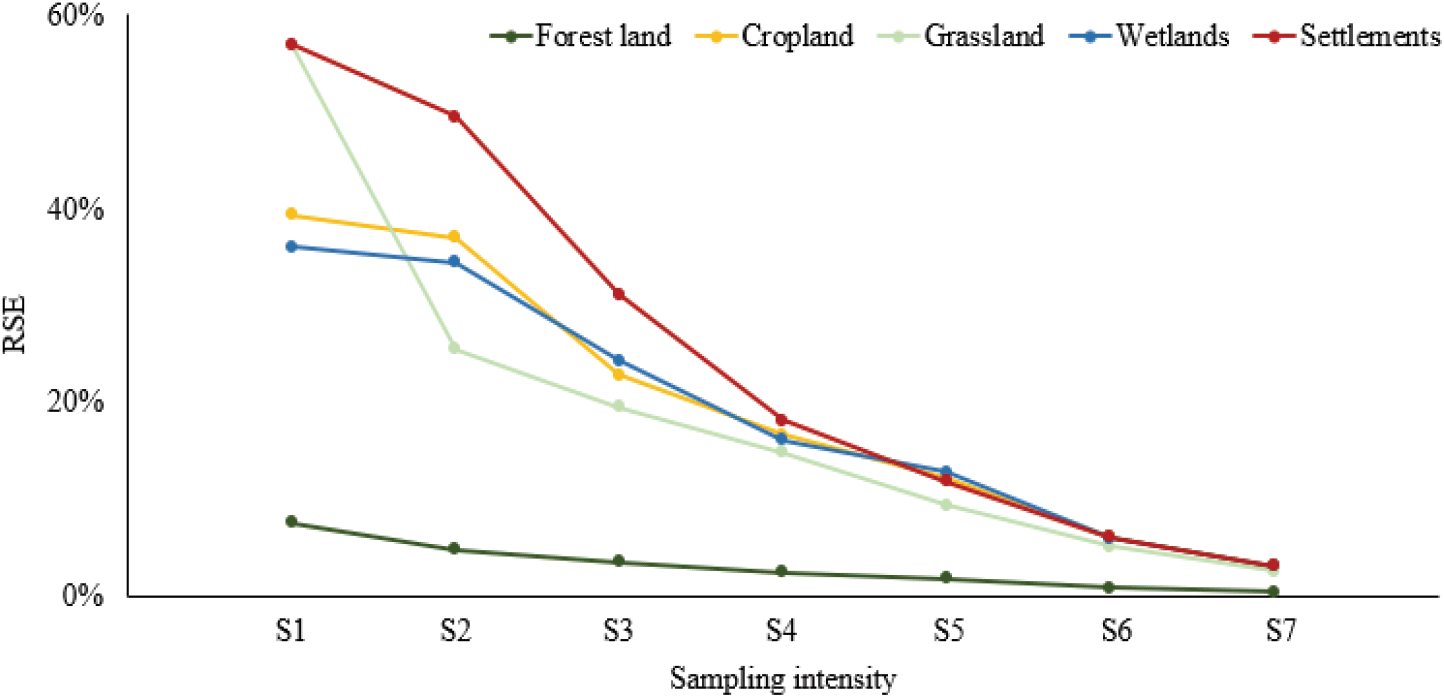
표본강도에 따라 토지피복범주별 RSE를 산출한 결과, 전체적으로 표본강도가 증가할수록 RSE가 감소하였다(Figure 7). 표본강도가 가장 낮은 S1에서 면적이 가장 큰 산림지의 RSE는 약 8%로 낮게 산출되었으며, 초지와 정주지가 평균 약 57%, 농경지와 습지가 평균 약 38%로 산림지를 제외한 범주의 RSE가 크게 분포하였다. S4부터산림지를 제외한 범주의 RSE가 평균 약 16%로 범주 간의 RSE의 범위가 감소하였으며, 표본강도가 가장 큰 S7의 경우 RSE가 산림지 0%, 농경지, 초지, 습지, 정주지 각각 3%로 낮게 수렴하였다. 산림지는 표본강도가 낮더라도 RSE가 10% 미만으로 분포하였지만, 산림지 외의 토지피복범주는 RSE가 크게 변화하였다. 이는 연구대상지 특성상 세분류 토지피복지도를 기준으로 산림지를 제외한 다른 범주의 면적 비율이 10% 이하로 분포하여 각 토지피복범주 대한 표본이 부족하기 때문에 RSE가 높게 산출된 것으로 판단된다. 한편, 국외에서 sampling method를 이용하여 토지피복면적을 산출한 사례에 따르면, 토지이용변화의 불확실성을 산림지의 경우 5~15%, 농경지와 초지의 경우 5~10%로 제시하고 있으며, Intergovernmental Panel on Climate Change(2006)는 불확도를 실용적인 한 감소시켜야 하며 토지이용변화 매트릭스의 낮은 불확도의 범위를 10~15%로 제시하고 있다. 따라서, RSE가 산림지 2%, 농경지 12%, 초지 9%로 산출된 S5 이상의 표본강도가 적합한 것으로 판단된다(Table 6)(Yim et al., 2020; Blujdea et al., 2015).
표본강도에 따른 RE는 RSE의 범위가 감소하고, 표본강도 중 중간단계에 해당하는 S4를 기준으로 분석한 결과, 표본강도가 증가할수록 상대효율의 감소폭이 작아지는 경향을 보였다. 이는 일반적으로 표본강도가 증가하면 표본의 데이터가 많아짐에 따라 더욱 정밀해져 상대 효율이 증대되는 선행 연구와 동일하였다(Yim et al., 2009). 한편, 카이제곱 검정을 통해 토지피복지도와 각 표본강도의 토지피복면적 비율의 적합성을 검정한 결과, 표본강도가 증가함에 따라 카이제곱 통계량이 감소하였지만, 기대빈도가 5 이하인 S1을 제외하고 유의수준 0.1에서 모든 표본강도에서 토지피복지도 면적 비율과 유의한 차이는 보이지 않았다(Table 7).
Table 7.
Relative efficiency and chi-square test according to sampling intensity.
|
Sampling intensity |
Var(RSE) |
RE
|
χ2(n=5) |
p-value |
Significant at 90% |
|
S1 |
4.1 |
10.38 |
- |
- |
|
|
S2 |
2.8 |
6.90 |
2.842 |
0.585 |
No |
|
S3 |
1.1 |
2.63 |
2.424 |
0.658 |
No |
|
S4 |
0.4 |
1.00 |
1.067 |
0.899 |
No |
|
S5 |
0.2 |
0.51 |
2.700 |
0.609 |
No |
|
S6 |
0.1 |
0.12 |
0.668 |
0.955 |
No |
|
S7 |
0.0 |
0.03 |
1.048 |
0.903 |
No |
Download Excel Table
국가산림자원조사의 표본강도는 4 × 4 km로 본 연구에서의 S1 표본강도와 동일하게 시행하고 있다. 또한, 산림지는 S1 표본강도에서 RSE가 약 8%로 산출되었으며, 이후 표본강도에서도 점차 감소하는 추세를 보였다. 이에 따라, 산림지에 대한 모니터링은 S1 표본강도도 적합한 것으로 판단된다. 하지만, 본 연구의 대상지가 시군구 단위로 충분한 면적이 확보되지 않아 S1 표본강도에 대한 통계적 검정은 불가능하여 향후, 도단위 또는 국가 단위에서의 추가적인 연구가 필요하다고 판단된다. 한편, 온실가스 인벤토리에 대한 통계를 작성하기 위해서는 산림지뿐만 아니라 농경지, 초지, 습지, 정주지에 대한 모니터링이 필요하다. 본 연구 결과를 바탕으로 시군구 단위에서는 모든 범주의 RSE가 IPCC 기준을 만족하고, 통계적 검정이 가능한 S5 표본강도가 가장 적합한 것으로 판단된다. 따라서, 적절한 표본강도를 선택하기 위해서는 대상지에 대한 범위, 분류범주 등 다양한 조건이 고려되어야 하고, 이를 바탕으로 모니터링 대상의 조건에 따라 표본 강도를 선정한다면 더욱 비용·효율적인 모니터링이 이루어질 것으로 기대된다.
결 론
본 연구는 육안판독을 통해 100 × 100 m 크기의 항공사진 5,000장의 데이터세트를 선정하여 학습과 검증 과정을 통해 딥러닝 기반의 토지피복분류 모델을 구축 및 평가하였으며, 샘플링 강도에 따라 추출한 이미지에 분류 모델을 적용하여 토지피복면적을 추정하였다. 딥러닝과 sampling method를 이용하여 추정된 토지피복 면적은 표본강도가 높아짐에 따라, 일정한 판독 기준에 의해 만들어진 세분류 토지피복지도에 준한 토지피복 면적을 추정할 수 있었다.
딥러닝 모델은 VGG16 모델을 이용하였으며, 구축된 모델은 OA와 Kappa의 값이 각각 91.1%, 88.8%으로 산출되었다. 표본강도는 계통추출법을 이용하여 250 m~4 km 7종류의 데이터세트를 구축하였으며, 구축된 모델을 표본강도에 따라 구축된 이미지에 적용하고 토지피복면적을 추정하였다. 표본강도에 따라 구축된 토지피복면적과 토지피복지도와 비교한 결과, 표본강도가 증가할수록 전체정확도와 카파계수는 감소하였지만, 토지피복면적 비율의 차이는 감소하였다. 추정된 토지피복면적에 대해 상대표준오차, 상대효율을 산출한 결과, 표본강도가 높을수록 상대표준오차와 상대효율은 감소되었다. 또한, 적합도 검정 결과, S1을 제외한 모든 표본강도에서 토지피복지도와의 면적비율이 유의한 차이를 보이지 않았다. 하지만, 국외사례 및 IPCC 가이드라인의 불확도 산출 사례에 따르면 S5 이상의 표본강도를 활용하는 것이 적합하다고 판단된다.
또한, 최적의 표본강도를 선정하는데 있어 가장 큰 요소는 불확도로 볼 수 있으며, 모델의 성능이 향상된다면 더 낮은 표본강도에서도 효율적으로 활용할 수 있을 것으로 기대된다. 특히, 모델의 성능은 구축된 데이터세트에 따라 달라질 수 있다. 데이터세트의 이미지 크기가 작을 때는 표본점의 토지피복정보가 충분히 추출되지 않을 수 있고, 클 때는 표본점뿐만 아니라 주변 지역의 토지피복범주가 혼재되어 이미지 분류의 정확도가 낮아질 수 있다. 따라서, 사용하는 표본 강도와 이미지 자료 등을 고려한 최적의 이미지 크기를 설정하기 위한 후속 연구가 필요할 것으로 판단된다. 또한, 데이터세트 확대 및 범주의 세분화, 학습률·학습횟수 등의 딥러닝 모델의 하이퍼파라미터 최적화를 통해 모델의 성능을 향상 시킬 수 있을 것으로 기대된다.
한편, 본 연구에서 제시한 결과는 준국가수준의 결과로써, sampling method를 이용하여 면적 추정 시 초지, 습지, 정주지에 대한 표본수가 작아 표본강도 대비 상대표준오차가 크게 산출되었다. 따라서, 국가수준의 온실가스 인벤토리 구축을 위해서는 전국을 대상으로 한 데이터 구축과 딥러닝 기반의 sampling method에 대한 연구가 필요할 것으로 판단된다.
감사의 글
본 연구는 산림청(한국임업진흥원) 산림과학기술 연구개발사업 ‘(2021359B10-2223-BD01)’의 지원에 의하여 이루어진 것입니다.
References
Abdalla, A., Cen, H., Wan, L., Rashid, R., Weng, H., Zhou, W. and He, Y. 2019. Fine-tuning convolutional neural network with transfer learning for semantic segmentation of ground-level oilseed rape images in a field with high weed pressure. Computers and Electronics in Agriculture 167: 105091.


Bergado, J.R., Persello, C. and Gevaert, C. 2016. A deep learning approach to the classification of sub-decimetre resolution aerial images. In 2016 IEEE International Geoscience and Remote Sensing Symposium. pp. 1516-1519.
Blujdea, V.N., Viñas, R.A., Federici, S. and Grassi, G. 2015. The EU greenhouse gas inventory for the LULUCF sector: I. Overview and comparative analysis of methods used by EU member states. Carbon Management 6(5-6): 247-259.
Cui, B., Chen, X. and Lu, Y. 2020. Semantic segmentation of remote sensing images using transfer learning and deep convolutional neural network with dense connection. Ieee Access 8: 116744-116755.
Greenhouse Gas Inventory and Research Center. 2021. 2021 National Greenhouse Gas Inventory Report of Korea. Seoul: Greenhouse Gas Inventory & Research Center of Korea. pp. 259
Hamedianfar, A., Mohamedou, C., Kangas, A., amd Vauhkonen, J. 2022. Deep learning for forest inventory and planning: a critical review on the remote sensing approaches so far and prospects for further applications. Forestry 95(4): 451-465.
Holt, D., Scott, A. J. and Ewings, P.D. 1980. Chi‐squared tests with survey data. Journal of the Royal Statistical Society: Series A (General) 143(3): 303-320.
Huang, J., Weng, L., Chen, B. and Xia, M. 2021. DFFAN: dual function feature aggregation network for semantic segmentation of land cover. ISPRS International Journal of Geo-Information 10(3): 125.
Intergovernmental Panel on Climate Change. 2003. Good Practice Guidance for Land Use, Land-Use Change and Forestry. Kanagawa. Japan. pp. 5.9.
Intergovernmental Panel on Climate Change. 2006. 2006 IPCC Guidelines for National Greenhouse Gas Inventories. Kanagawa. Japan. pp. 4.36.
Intergovernmental Panel on Climate Change. 2019. 2019 Refinement to the 2006 IPCC Guidelines for National Greenhouse Gas Inventories. Kanagawa. Japan. pp. 1.10.
Jo, W.H., Lim, Y.H. and Park, K.H. 2019. Deep learning based land cover classification using convolutional neural network: a case study of Korea. Journal of the Korean Geographical Society 54(1): 1-16.
Jung, Y.J., Yim, J.S. and Kim, J.S. 2020. Improving institutional arrangements to enhance GHG inventory of the LULUCF sector. Journal of Climate Change Research 11(6-2): 729-738.
Kavzoglu, T. and Colkesen, I. 2013. An assessment of the effectiveness of a rotation forest ensemble for land-use and land-cover mapping. International Journal of Remote Sensing 34(12): 4224-4241.
Kiala, Z., Mutanga, O., Odindi, J. and Peerbhay, K. 2019. Feature selection on sentinel-2 multispectral imagery for mapping a landscape infested by parthenium weed. Remote Sensing, 11(16): 1892.
Kim, H.W., Kim, M.H. and Lee Y.W. 2022. Research trend of the remote sensing image analysis using deep learning. Korean Journal of Remote Sensing 38(5): 819-834.
Kim, J.H. and Choi, I.H. 2012. The Management Status and Civic Consciousness Analysis on the Urban Forests in Chuncheon. Journal of Forest Science, 28(1): 46-55.
Korea Forest Service and Korea Forestry Promotion Institute. 2021. The 8th national forest inventory and forest health monitoring. -Field manual-. Seoul: Korea Forestry Promotion Institute. pp. 5.
Korea Forest Service. 2022. Statistical yearbook of forestry. Daejeon: Korea Forest Service. pp. 36.
Landis, J.R. and Koch, G.G. 1977. The measurement of observer agreement for categorical data. biometrics. pp. 159-174.
,

Moon, G.H., Yim, J.S. and Moon, N.H. 2021. Optimal sampling intensity in South Korea for a land-use change matrix using point sampling. Land, 10(7): 677.
Moon, S.B. 2017. Understanding Basic Statistic. Shinjeong. Seoul, Korea. pp. 549
Muhammad, U., Wang, W., Chattha, S.P. and Ali, S. 2018. Pre-trained VGGNet architecture for remote-sensing image scene classification. In 2018 24th International Conference on Pattern Recognition. pp. 1622-1627.
Naushad, R., Kaur, T. and Ghaderpour, E. 2021. Deep transfer learning for land use and land cover classification: A Comparative Study. Sensors, 21(23): 8083.
,
,

National Institute of Forest Science. 2021. 2019 Refinement to the 2006 IPCC guideline for national greenhouse gas inventories. Seoul. Korea: National Institute of Forest Science. pp. 74.
Park, J.M., Sim, W.D. and Lee, J.S. 2019. Automatic Classification by land use category of national level LULUCF sector using deep learning model. Korean Jouranl of Remote Sensing, 35(6): 1053-1065.
Rakshit, S., Debnath, S., and Mondal, D. 2018. Identifying land patterns from satellite imagery in amazon rainforest using deep learning. arXiv preprint arXiv:1809.00340.
Ramadhani, F., Pullanagari, R., Kereszturi, G. and Procter, J. 2020. Mapping of rice growth phases and bare land using Landsat-8 OLI with machine learning. International Journal of Remote Sensing, 41(21): 8428-8452.
Simonyan, K. and Zisserman, A. 2014. Very deep convolutional networks for large-scale image recognition. arXiv: 1409.1556.
Smith, P. et al. 2014. Chapter 11 - Agriculture, forestry and other land use. In: Climate Change 2014: Mitigation of Climate Change. IPCC Working Group III Contribution to AR5. Cambridge University Press. pp. 16.
Song, A.R., Choi, J.W. and Kim, Y.I. 2019. Change detection for high-resolution satellite images using transfer learning and deep learning network. Journal of the Korean Society of Surveying, Geodesy, Photogrammetry, and Cartography, 37(3): 199-208.
Um Y.H. 2013. Assessing classification auccuracy using cohen’s kappa in data mining. Journal of the Korea Society of Computer and Information, 18(1): 177-183.
Yang, C., Rottensteiner, F. and Heipke, C. 2018. Classification of land cover and land use based on convolutional neural networks. ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences 4 2018, Nr. 3, 4(3): 251-258.
Yang, C., Rottensteiner, F. and Heipke, C. 2019. Towards better classification of land cover and land use based on convolutional neural networks. The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences; 42-2/W13, 42(2/W13): 139-146.
Yim, J.S., Moon, G.H., Park, J.M. and Shin, M.Y. 2020. Comparison of uncertainty in the land-use change matrix by sampling intensity. Journal of Climate Change Research 11(3): 203-213.
Yoo, S.J. and Yoon, B.S. 2018. Implementation of the GHGs reduction target from business as usual emissions under Paris agreement. The Yonsei Law Review, 28(2): 289-317.
Zhou, K., Ming, D., Lv, X., Fang, J. and Wang, M. 2019. CNN-based land cover classification combining stratified segmentation and fusion of point cloud and very high-spatial resolution remote sensing image data. Remote Sensing, 11(17): 2065.