



서 론
식물은 가장 흔히 접할 수 있는 자연물로서, 급격한 도시화에 따라 식물에 대한 시민들의 관심이 점차 증가하고 있다. 이러한 식물의 이름을 확인하는 동정(Identification)은 일반 대중, 그리고 전문가들에게도 까다로운 작업이며, 식물의 높은 다양성과 종간 유사도 때문에 오류에 취약하고, 많은 경험이 요구된다(Mata-Montero and Carranza-Rojas, 2016). 한편, 스마트폰의 보급과 기계 학습 기법의 빠른 발전에 힘입어, 이러한 문제점을 극복하기 위하여 자동 식물 인식 기술에 대한 연구가 빠르게 증가하고 있다(Kim, 2019). 일반적으로 수목의 식별은 잎(leaf), 과실(fruit), 꽃(flower), 수피(bark) 등에 나타나는 시각적인 정보를 통해 이루어지는데, 국내에서는 꽃을 이용한 분류가 가장 많이 시도되었고 또한 가장 높은 분류 성능을 보여주었다(Yoon et al., 2018). 이러한 연구들을 활용하여, 꽃과 잎의 형태적 정보로 종을 식별하는 “다음 꽃 검색”과 “8220;네이버 스마트렌즈” 등의 서비스들이 공개되었으나, 정확도 면에서 여러가지 한계점을 보여주었다(Choi, 2019).
더 나아가, 꽃이나 잎을 자동 인식에 활용할 때 여러가지 제약이 발생하는데, 각 기관은 특정한 계절 및 식물계절학적 시기에만 존재하고, 수관의 지하고가 높은 경우 접근성이 크게 떨어지게 된다(Ratajczak et al, 2019). 수피의 경우 이러한 제약에서 자유롭고, 접근성이 좋으며, 연중 변화가 적고, 수간(stem)의 전체적인 형태가 단순하여 자료를 수집하기가 용이하다는 장점이 있다(Carpentier et al., 2018; Ratajczak et al., 2019). 하지만 수피는 수령 및 환경에 따라 높은 종내 변이(intra-specific variance)를 보이기 때문에(Fiel and Sablatnig, 2011), 이를 극복하기 위해서는 다양한 변이를 반영하는 양질의 자료들이 요구되나, 국내에서 주로 볼 수 있는 수종에 대해서는 경우 기존의 국내외 연구에서 수집된 자료가 존재하지 않는 실정이다.
해외의 경우, 비교적 다양한 수종에 대하여 수피 사진 자료를 수집하고, 이후 기계 학습 기법을 적용하여 종을 분류하는 연구가 다수 수행되었다. 기계 학습 기법의 경우, 이전의 연구에서는 사람이 직접 고안한 특징 추출 기법과 전통적 기계 학습 알고리즘이 많이 활용되었고, 최근에는 알고리즘이 데이터로부터 직접 패턴을 찾아내는 딥러닝 기술이 많이 활용되는 추세이다. Huang(2006)은 신경망과 가버 웨이블릿(Gabor wavelets) 기법으로 수피의 질감 특징을 추출하여 방사상 기반 확률적 네트워크(radial basis probabilistic network, RBPNN)로 분류하는 연구를 수행하였고, 약 300개의 수피 사진에 대해 80%에 가까운 정확도를 얻었다. Boudra et al.(2015)은 영상의 질감과 얼굴인식 등에 사용되는 비교적 간단한 국부 이진 패턴(Local Binary Pattern, LBP)을 사용하였으며, Fiel and Sablatnig(2011)는 서포트 벡터 머신(Support Vector Machine, SVM)과 규모불변특성변환법(Scale-Invariant Feature Transform, SIFT)을 결합하여 호주연방산림(Austrian Federal Forests)에서 수집된 수피 자료에서 약 70%의 정확도를 도출하였다. 또한, Bressane et al.(2015)은 의사결정나무(Decision Tree) 기법을 바탕으로 수피 이미지를 분류하는 연구를 수행한 바 있다.
이러한 전통적 기계 학습 기법에서 한걸음 더 나아가, 최근에는 딥러닝 알고리즘을 이용하여 수피 정보로부터 수목을 식별하기 위한 다양한 시도들이 이루어지고 있다. Mizoguchi et al.(2017)은 레이저거리측정기(Light Detection And Ranging, LiDAR)를 이용하여 Japanese Cedar와 Japanese Cypress의 두 가지 수종에 대하여 10 m 거리에서 공간 해상도가 5 mm인 256 × 256 크기의 영상을 약 35,000개 제작한 후, 합성곱 신경망(Convolution Neural Network, CNN)의 일종인 AlexNet을 학습시켜 90% 정확도를 얻을 수 있었다(Krizhevsky et al., 2012). 최근 일반적인 가시광선 이미지(RGB)를 활용한 연구도 본격적으로 수행되고 있는데, Cimpoi et al.(2015)은 ImageNet(http://www.image-net.org/) 데이터셋에서 사전에 학습된 CNN과 SVM을 사용하여 수피의 다양한 질감을 분류하는 연구를 수행하였다. 그러나 앞서 언급된 바와 같이, 국내의 경우 이러한 인공지능 기반 수목 분류의 연구는 매우 미미한 상황이며 국내 수종에 대한 수피 자료 또한 존재하지 않는다.
따라서 본 연구에서는 국내 수종에 대하여 수피 사진 데이터셋을 구축하고, 선행 연구의 자료를 함께 활용하여 보다 다양한 수종에 대한 CNN의 수피 기반 동정의 가능성을 정량적으로 평가하고자 한다. 보다 구체적으로, 첫 번째, 국내에서 흔히 볼 수 있는 수종에 대해 적용 가능한 수피 사진 데이터베이스를 구축하고, 둘째, 두 가지 CNN 모형을 제작하고 성능을 정량적으로 평가 및 비교하여 모형의 복잡도가 성능에 미치는 영향을 분석하고, 마지막으로 모형 성능에 영향을 미칠 수 있는 다양한 요인을 평가하여 모형의 성능 향상을 위한 방안을 제시한다.
재료 및 방법
본 연구에서는 관악수목원과 서울, 경기도의 공원과 숲에서 발견된 39종의 나무에서 이미지를 수집하고 해외 선행연구 사례에서 많이 사용되었던 BarkNet 1.0 (Carpentier et al., 2018)에서 국내로 도입된 수종 및 촬영 수종과 중복된 수종을 17종 병합해 총 53종의 데이터를 수집했다(Table 1). 수집된 자료의 편향 및 중복을 피하기 위하여 데이터 수집 과정에서 다음과 같은 규칙을 준수하였다. 먼저 촬영할 대상 수목을 정하고 수목을 동정한 후, 수목의 흉고직경 크기에 따라 3방향 또는 4방향에서 한 장씩 촬영했다. 이때 촬영은 사진을 찍은 조건(방해물, 수목 크기 등)에 따라 수간에서 20~60 cm 떨어진 거리에서 진행했다. 촬영 기기는 일반적인 휴대폰 카메라를 사용하였으며(IPhone SE 2), 이후 전처리 작업을 수월하게 할 수 있도록 수간이 사진의 수직 축과 평행하도록 촬영하였다.
또한, 사진 영상 자료의 다양성을 높이기 위해 가능한 상이한 조건에서 같은 수종에 대한 사진 촬영을 진행하였다. 조명 가변성을 높이기 위해 촬영 시간을 오전 6시부터 오후 6시로 설정하였으며, 다양한 날씨 조건에서 사진을 촬영하였다. 촬영 장소 또한 대학 캠퍼스나 공원과 같은 개방된 지역을 비롯하여 숲 속과 같이 수목 밀도와 울폐도가 높은 장소에서 다양하게 사진 자료가 수집되었다. 이는 수관에 의해 형성된 음영과 빛의 반사가 사진 자료에 미치는 영향을 고려하기 위함이다. 이렇게 2020년 9월부터 11월까지 약 10,000 여장의 사진 자료가 수집되었다.
촬영된 사진은 수종별로 파일을 분류하고, 흐릿하거나 과도하게 조명 조건에 영향을 받은 사진들을 제거하고, 이후 수피에 해당하는 부분만을 편집하여 저장하였다(Figure 1). 그림에서 나타난 것처럼, 사진 분할 과정이 동시에 수행되었는데, 이는 영상 자료의 양을 늘려줄 뿐만 아니라, 모형의 처리 속도를 향상시킬 수 있다는 장점이 있다(Carpentier et al., 2018). 모든 사진 자료는 331 × 331 픽셀 크기로 분할되었고, 제작된 총 분할 사진의 수는 219,742개이다.
한편, 본 연구에서 구축한 원본 수피 사진 자료들을 웹 상에 공개하여, 누구나 접근 가능하도록 하였다(https://doi.org/10.5281/zenodo.4749062).

합성곱신경망(CNN)은 딥러닝 알고리즘의 하나로 사진과 같은 영상 이미지를 추상화하는 성능이 우수하여 영상 인식과 분류 문제 해결에 많이 사용되고 있다. 합성곱신경망 모형은 합성곱층(convolution layer), 통합층(pooling layer), 활성화 함수(activation function), 묶음정규화과정 (batch normalization), 제거과정(drop out), 완전연결층(fully connected layer)으로 구성되어 있다(Hayat, 2017). 합성곱층에서는 입력되는 데이터에 합성곱 필터를 사용하여 모델의 파라미터 수를 최소화하고, 영상 자료를 가장 잘 분류할 수 있는 특징을 찾는다(Min, 2020). 통합층은 특징을 강화하고 모으는 역할을 하고, 활성화 함수는 신경망의 출력에 영향을 주는 함수로, 정류선형단위함수(Rectified Linear Unit, ReLU) 등이 있다(Hayat, 2017). 묶음정규화과정은 활성화 함수의 활성화 값과 출력값을 정규화하며, 제거과정은 학습 단계마다 확률적으로 일부 뉴런을 제거함으로써 어떤 특징이 특정 뉴런에 고정되는 것을 막아 가중치의 균형을 잡도록 하는 것인데, 이를 통해 과적합을 방지할 수 있다. 완전연결층은 분류를 목적으로 망의 끝에서 사용되는데, 이전 층에서 입력된 것을 출력층 전체에 연결한다. 위의 구성 요소들의 조합에 따라 무수히 많은 CNN 모델이 존재하지만, 본 연구에서는 간단한 구조이면서도 높은 성능을 보이는 VGGNet을 활용하였다(Simonyan and Zisserman, 2015).
VGGNet은 신경망의 처음부터 끝까지 3 × 3 합성곱과 2 × 2 최대통합층(max-pooling)을 번갈아 가며 사용하는 단순한 구조이다. 신경망의 끝부분에는 제거과정이 적용된 완전연결층이 3개 있으며, 마지막 출력 부분은 softmax 활성함수로 입력에 대한 출력의 결과를 확률적으로 나타낸다. VGGNet은 3 × 3 합성곱층을 여러 개 쌓는 구조를 사용했기 때문에 신경망 파라미터 수를 줄이고, 늘어난 층의 수 만큼 여러 개의 활성함수를 사용할 수 있게 되어 더 큰 비선형성을 확보하였다. VGGNet은 합성곱 및 통합층의 깊이에 따라 모델이 구분되는데 16, 19층으로 구성된 VGG16, VGG19를 활용하였다. 기존의 두 VGG 모형이 ImageNet 데이터셋에 대해 학습된, 1,000개의 분류 클래스로 구성된 모형이기에, 본 연구의 조건과 맞도록 마지막 분류층을 53개의 분류 클래스를 가지도록 다시 제작하였다.
실험에 케라스(Keras, Python으로 작성된 열린 신경망 라이브러리)에서 사전 훈련된 네트워크인 VGG16, VGG19를 가져와 사용하였다. 일반적으로 초기의 합성곱층은 분류 대상에 관계없이 경계면, 색상 등의 일반적인 특징을 잡아내므로, 기존의 데이터셋에서 잘 학습이 되었다면 다시 학습시킬 필요가 없다. 이에 따라, 본 연구에서는 마지막 완전연결 분류층을 제외하고는 가중치 갱신이 일어나지 않도록 하여 학습을 제한하였다. 이미 학습이 완료된 모델을 가져와 재학습시키는 것이므로, 학습률은 0.0001로 낮게 설정하여 진행하였다. 정규화를 위해 묶음크기(batch size)는 32로 설정하고, 각 층에 묶음정규화 기법을 활용하였고, 완전연결 분류층에 0.5의 강도로 제거과정을 적용하였다. 최종적으로 총 10세대(epoch)에 걸쳐 신경망을 학습시켰고, 최적화에는 Adam Optimizer를 적용하였다.
수집한 자료데이터 세트에서 각각의 수종의 분할사진을 무작위로 선택해 75%는 학습시키고 나머지 25%는 검증의 용도로 사용했다. 모형의 성능 비교 후에 높은 정확도를 가진 모형을 선정하여 해당 모델로 아래 실험을 추가적으로 진행하였다.
본 연구를 통해서 수집된 자료 이외의 수종, 즉 학습되지 않은 수종의 수피에 대한 동정을 시도하였다. 학습되지 않은 수종으로는 갈졸참나무(Quercus × urticifolia), 고로쇠나무(Acer pictum subsp.mono), 레지노사소나무(Pinus resinosa), 루브라참나무(Quercus rubra), 붉은가문비(Picea jezoensis)의 총 5 수종을 사용하였다. 각각 100장의 사진에 대한 모형의 결과를 정리하여 입력된 수종과 같은 속 또는 과의 결과가 어느 정도 나타나는지 분석하였다.
결과 및 고찰
VGG16과 VGG19에 대해 2.3.1절에서 기술된 동일한 학습률, 묶음정규화, 제거율 등의 조건에서 학습시켰을 때, 10 세대의 학습 이후 VGG16은 90.41%, VGG19는 92.62%의 검증 데이터 정확도를 보였으며(Table 2), 10세대 이상의 학습에서는 학습 데이터 정확도는 증가했지만 검증 데이터 정확도는 오히려 떨어지거나 비슷하게 유지되는 것을 확인하였다. 가장 높은 정확도가 기록된 10세대에서도 학습 데이터와 검증 데이터간의 성능 차이가 약 6% 이상으로 크게 나는 것으로 미루어 볼 때, 과적합(Overfitting) 경향을 확인할 수 있고, 이러한 이유 때문에 추가적인 학습에서도 성능 향상이 이루어지지 않았음을 해석할 수 있다.
| CNN architecture | Train loss | Train accuracy (%) | Validation loss | Validation accuracy (%) |
|---|---|---|---|---|
| VGG16 | 0.1041 | 96.48 | 0.3049 | 90.41 |
| VGG19 | 0.1062 | 96.42 | 0.2323 | 92.62 |
한편, 모형의 네트워크 깊이가 더 깊은 VGG19 모델의 영상 분류 정확도가 높은 것을 알 수 있었는데, 본 연구에서 VGG 네트워크 깊이를 최대 19까지만 사용한 이유는 모델 개발 당시의 데이터에서 분류 오차율이 19층에서 수렴했기 때문인데(Simonyan and Zisserman, 2015), 충분한 사진 자료를 수집한 뒤에 최근에 개발된 더 좋은 성능을 보이는 복잡한 구조의 신경망 모델을 적용할 경우 더 높은 성능을 보일 수 있음을 짐작할 수 있다.
모형의 정확도가 높은 VGG19 모형을 기준으로 자료 구축에 필요한 영상자료의 수를 추정하기 위해 하나의 세대(1 epoch)의 학습에 사용된 영상자료의 숫자에 따른 모형의 정확도를 Figure 2에 나타내었다. 그림에서 학습 및 검증에 활용된 분할 사진의 수가 늘어날수록 분류 정확도도 높아지는 경향을 확인할 수 있었는데, 2,000장 미만의 사진에 대해서는 38.99%에서 높게는 100%까지 분류 정확도가 넓은 분포 범위를 가지는 것을 확인하였다. 데이터의 수가 적은 경우, 모델은 학습 당시 이용된 데이터에 강하게 의존할 수밖에 없고, 성능 검증 또한 적은 데이터에 의존하여 평가가 이루어지게 되므로 높은 변이의 정확도가 도출된다. 한편, 2,000장 이상의 사진에 대해서는 모든 수종이 80% 이상의 정확도를 보여주었고, 데이터의 수가 늘어날수록 그 정확도가 100%에 근접해가는 것을 확인할 수 있었다. 이러한 경향을 더욱 정확히 확인하기 위해서는 기존의 수종들에 대한 추가적인 자료 축적과 새로운 종들에 대한 자료 수집이 필요할 것으로 판단된다.
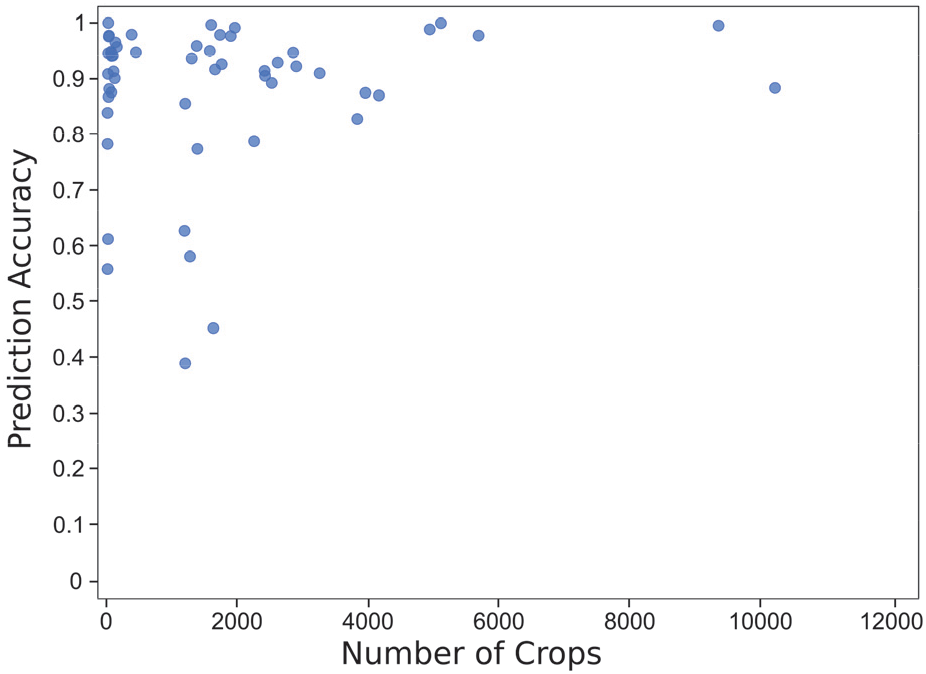
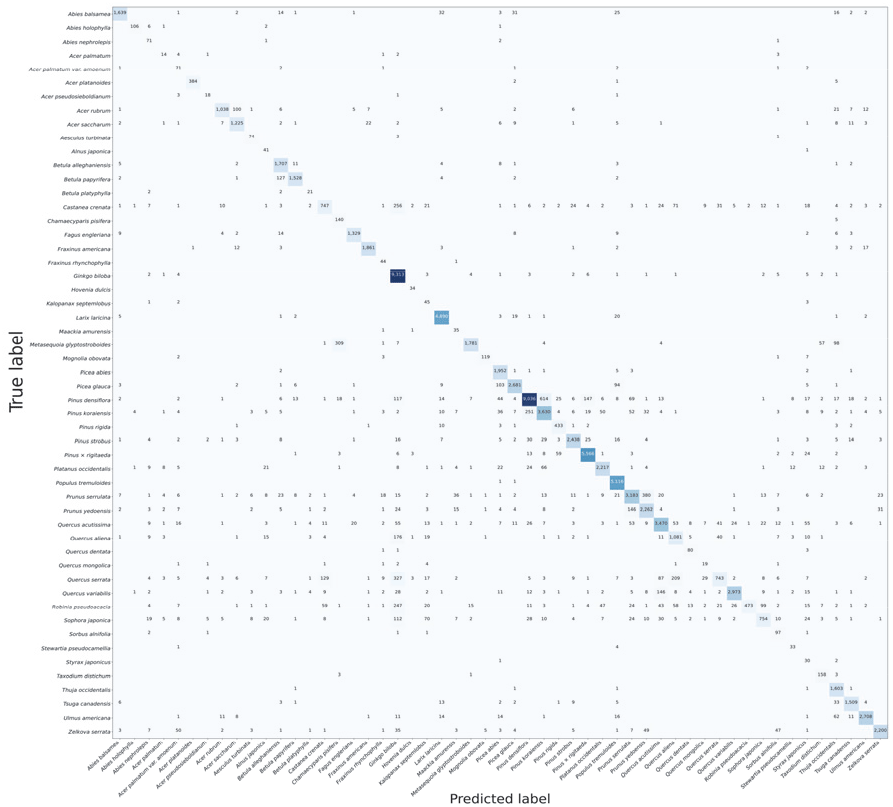
Figure 3은 VGG19를 통해 분류한 수피 이미지 데이터의 혼동 행렬이고, 행렬 내에 색상이 짙을수록 분류된 데이터의 수가 많음을 나타낸다. 그러나 수종별로 학습 및 검증에 활용된 있는 데이터양이 불균일하여 일부 수종만 색상이 짙게 나타났다. 따라서 각 수종별 영상자료의 수로 나누어 정규화시켜 Figure 4에 나타내었다. 대각선에 배치된 숫자가 높을수록 정확도가 높음을 나타내며, 해당 그림을 통해 본 연구를 통해 수집된 수종들에 대해 신경망 모델이 전반적으로 높은 정확도를 보여주었음을 확인할 수 있다.
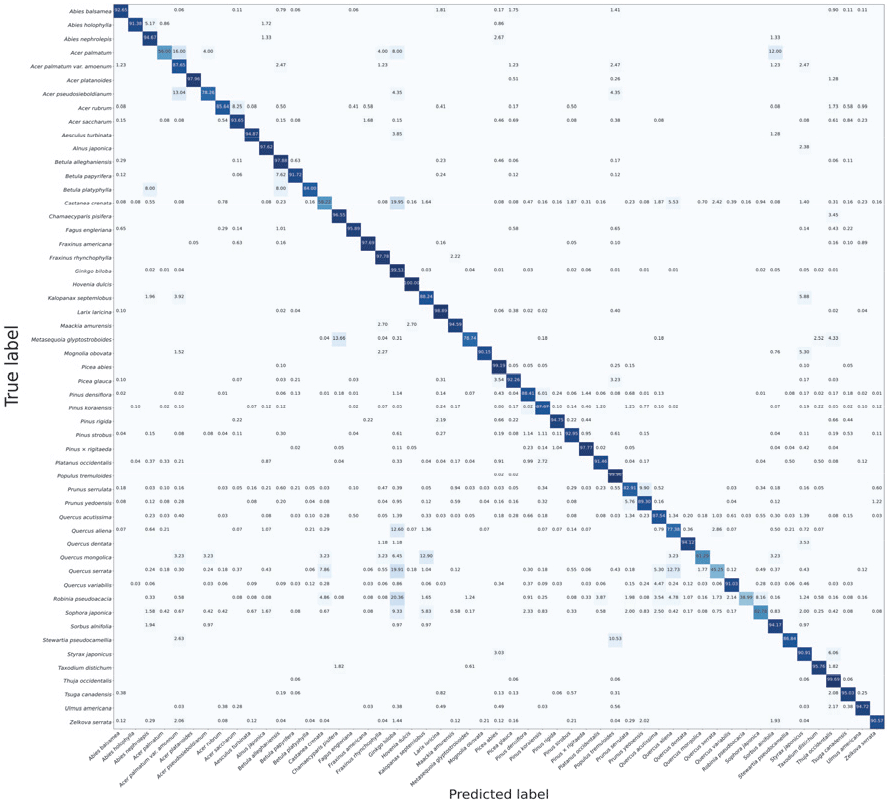
그러나 일부 수종의 분류과정에서 상당량의 영상자료가 같은 수종으로 잘못 분류되는 결과가 존재했다. 갈참나무(Quercus aliena)의 13%, 밤나무(Castanea crenata)의 20%, 아까시나무(Robinia pseudo-acacia)의 20%, 졸참나무(Quercus serrata)의 20%가 은행나무(Ginkgo biloba)로 잘못 동정되었으며, 단풍나무(Acer palmatum)의 16%, 당단풍나무(Acer pseudosieboldianum)의 13%가 일본왕단풍(Acer palmatum subsp. Amoenum)으로 잘못 분류되었다. 분류과정에서 발생한 이러한 문제의 원인을 찾기 위해 은행나무로 분류된 갈참나무, 밤나무, 아까시나무, 졸참나무와 일본왕단풍으로 분류된 단풍나무와 당단풍나무를 각각의 은행나무 집단, 일본왕단풍 집단으로 묶어 특성에 대해 비교하였다.
Figure 5는 갈참나무와 은행나무의 분할사진을 연속적으로 보여준 것이다. 사진자료를 보면 알 수 있듯이 맨눈으로 구분하기 어려울 정도로 두 수종 모두 세로로 깊게 갈라진 수피 형태를 보이는 것으로 나타났다(Park, 2013). 또한 영상 자료의 양적 측면에서 갈참나무, 밤나무, 아까시나무, 졸참나무는 각각 2068, 1705, 1605, 2215개의 분할사진 자료를 갖고 있는 반면 은행나무는 12,498개의 사진자료를 보유하고 있다. 오차가 발생하는 이유는 비슷하게 깊게 패인 수피의 형태적인 유사성과 은행나무의 사진 자료가 다른 수종에 비하여 월등하게 높기 때문에 발생한 학습의 불균형 때문이라고 판단된다.

이와 유사하게, Figure 6은 단풍나무, 당단풍나무와 일본왕단풍의 분할사진을 나열한 것이다. 은행나무 집단에서와 마찬가지로 맨눈으로 구분하기 어려울 정도로 같은 집단에 포함되는 세 수종 모두 세로로 얕게 갈라진 수피 형태를 보이는 것으로 나타났다(Park, 2013). 또한, 수집된 자료의 양에서는 단풍나무, 당단풍나무, 일본왕단풍은 각각 100, 94, 326개의 분할사진을 갖고 있다. 비록 은행나무 집단과는 다르게 일본왕나무 집단의 경우, 수종별 필요 사진자료인 2,000장에 미치지 못하여 정확도가 높지 않을 수 있지만, 은행나무 집단과 마찬가지로, 사진자료의 양이 많은 일본왕단풍으로 나머지 두 수종을 잘못 분류하였다는 공통점이 있다.

따라서, VGG19를 통한 수목 동정의 과정에서 잘못 판정되는 원인 중의 하나로, 은행나무 집단과 일본왕단풍 집단의 분석을 통해 학습된 정보량의 불균일 때문이라고 유추할 수 있다. 따라서 자료 구축을 위해서는 수종별 최소 2,000장 이상의 분할사진 영상과 균일한 양의 자료가 학습을 위해 사용되는 것이 바람직하다.
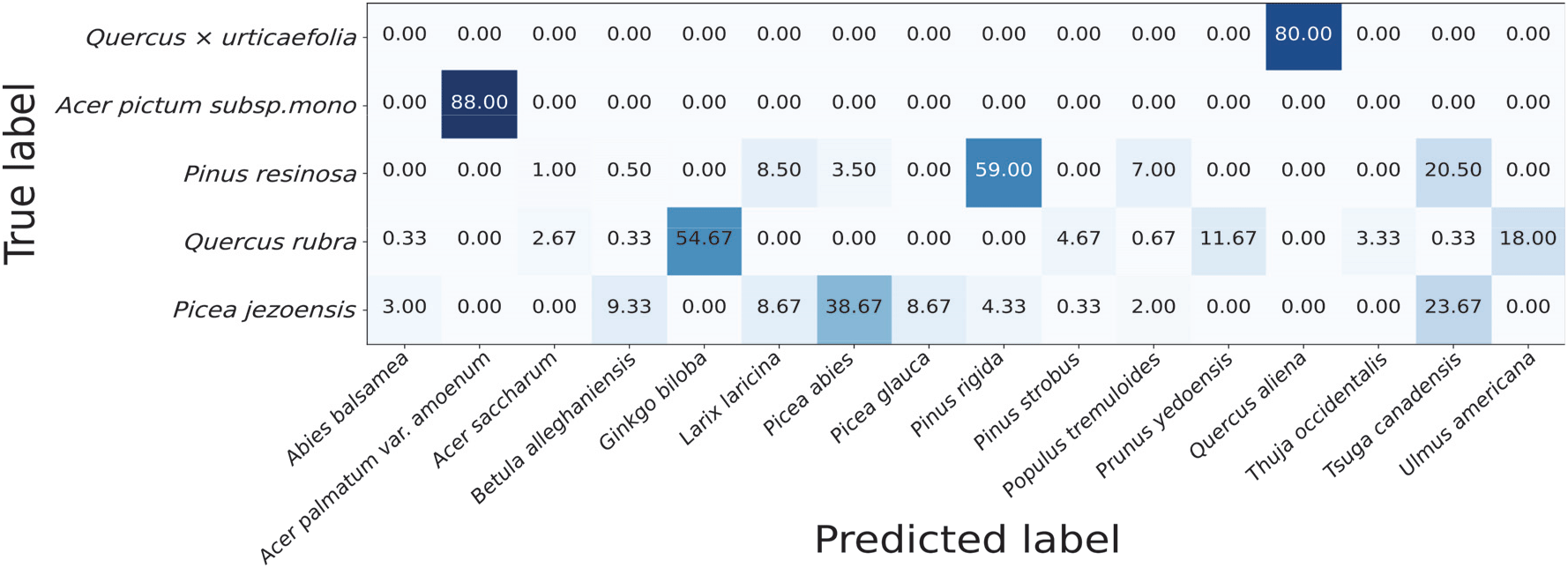
Figure 7은 수집된 자료에 포함되지 않은 갈졸참나무(Quercus × urticaefolia), 고로쇠나무(Acer pictum subsp.mono), 레지노사소나무(Pinus resinosa), 루브라참나무(Quercus rubra), 붉은가문비(Picea jezoensis)에 대한 동정 결과를 보여준다. 갈졸참나무는 80.00%를 갈참나무로, 그리고 2.35%를 떡갈나무로 분류하였고, 고로쇠나무는 88.00%를 일본왕단풍, 4.00%를 당단풍나무로 동정하였다. 한편, 아래의 세 수종에 대해서는 상대적으로 동일 속 내의 다른 종으로 분류한 비율이 상대적으로 적었는데, 레지노사소나무는 소나무속을 기준으로 59.00%를 리기다소나무로, 소나무과를 기준으로 91.50%를 리기다소나무, 캐나다솔송, 아메리카낙엽송 독일가문비나무로 나타났다. 붉은가문비는 가문비속을 기준으로 47.34%를 독일가문비와 코니카가문비로, 소나무과를 기준으로 87.01%를 독일가문비, 코니카가문비, 아메리카낙엽송, 캐나다솔송, 발삼전나무 등으로 인식하였다. 그러나 루브라참나무의 경우, 54.67%의 비율로 은행나무로 잘못 인식하였고, 같은 속 또는 과 내의 다른 종으로 전혀 분류하지 않는 결과를 나타냈다. 이와 같이, 학습에 활용되지 않은 5개의 수종에 대한 모형의 반응을 확인했을 때, 루브라참나무를 제외한 4개의 수종들은 같은 속 또는 같은 과에 해당하는 수종들로 80% 이상 예측하는 것을 알 수 있었다. 루브라참나무의 경우, 보유한 데이터 내의 동일 속 또는 과의 수종과 다른 수피 특징을 가져, 같은 분류군으로의 동정이 어려웠던 것으로 해석할 수 있다.
위 결과들은 CNN의 더 큰 분류군으로의 일반화 능력에 대한 가능성을 보여준다. 실제로 Figure 4에서도, Abies, Acer, Betula, Picea, Pinus, Prunus, Quercus 속 내의 수종들은 오차를 보이는 경우에도 주로 같은 속 또는 과 내의 다른 종으로 혼동하였는데, 5.17%의 전나무가 분비나무로, 16%의 단풍나무와 13%의 당단풍나무가 일본왕단풍으로, 7.62%의 종이자작나무와 8.00%의 자작나무가 황자작나무로, 6.02%의 잣나무가 소나무로, 9.90%의 벚나무가 왕벚나무로 잘못 분류되는 결과를 보였다. 한편, 참나무속 수종들에 대해서는 5.30%와 12.73%의 졸참나무가 각각 상수리나무와 갈참나무로 분류되고, 3.23%의 신갈나무와 7.86%의 졸참나무가 같은 참나무과인 밤나무로 분류되기도 했으나, 은행나무와 음나무 등의 다른 과로 분류되는 비율도 높았다(Figure 4).
이는 CNN이 종 수준에서는 수종에 따라 오차를 보이기도 하지만, 더 큰 분류군 단위에서의 핵심 분류 형질을 성공적으로 인식하고 있다는 것을 의미한다. 하지만 본 연구에서 추가적인 분석을 위해 활용했던 수종이 5개로 적은 수이며, 완전히 일관된 결과를 보이지 않았다는 점에서 한계가 있으며, 추후 검증이 더 필요하다.
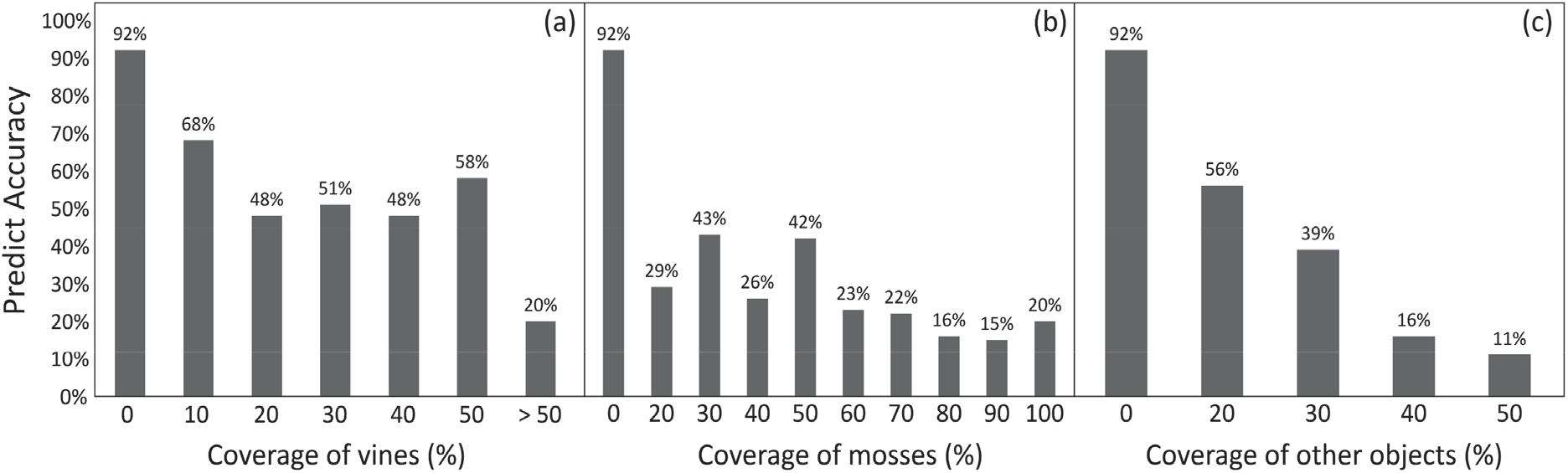
수피 사진자료를 이용해 분류하는 과정에서 오류를 발생시킬 것으로 예상되는 만경식물, 이끼와 기타(수피의 옹이, 상처 등)로 나눠 피도별 모형의 정확도를 계산하였다 (Figure 8). 만경식물[Figure 8(a)], 이끼[Figure 8(c)], 기타[Figure 8(b)]의 경우 20% 만큼의 피도가 존재할 때 정확도가 각각 48%, 43%, 56%로 피도가 존재하지 않을 때의 정확도 92%보다 크게 하락함을 확인할 수 있다. 또한, 피도가 높아질수록 정확도가 떨어지는 경향을 공통적으로 확인할 수 있다. 방해 조건을 두고 실험한 결과, 방해 요인의 종류에 상관없이 일반적인 수피 사진과 차이를 보일 때 모형의 정확도가 하락하는 것을 알 수 있었고, 따라서 모형을 활용할 경우 최대한 방해 요소의 개입을 피하는 것이 좋을 것으로 판단된다. 그러나 방해 요소의 유무와 관계없이 동정이 가능한, 현실적인 모델 구축을 위해서는 방해 요소가 포함된 더 많은 학습 자료를 준비하여 모형의 유연성을 높이거나, 한 개체목에서 추출된 여러 개의 분할 사진으로부터 다수결의 방식으로 판단하는 방법 등이 유효할 것으로 예상된다(Carpentier et al., 2018).
한편, 이러한 외적인 요소뿐만 아니라, 수령이나 환경에 따른 수피 자체의 큰 변이 또한 모형의 성능을 떨어뜨리는 주요한 요인이 될 수 있다. 수피는 연중 변화가 크지는 않으나, 수령에 따라서, 그리고 더 긴 시간 범위(10년 단위)에 있어서는 커다란 차이를 보이기도 한다(Ratajczak et al., 2019). 예를 들어, 성목 개체의 수피에서 크게 갈라지는 형태를 보이는 수종은 어린 개체에서는 얇은 줄무늬 혹은 갈라짐 정도로 형질이 나타나는 경우가 많고, 시간이 지남에 따라 껍질이 벗겨지는 양버즘나무와 같은 수종들은 성목 간에도 변이가 크다. CNN은 이미지로부터 다양한 특징을 추출하고 이러한 정보들을 종합하여 분류하게 되는데(Brodrick et al., 2019), 만약 수령과 환경에 따라 높은 변이를 보이는 갈라짐, 껍질 등의 특징을 분류에 활용할 경우 같은 수종으로 판단할 가능성이 낮아진다. 따라서 각 수종별로 이러한 요인에 따른 취약점을 알아보기 위하여 보다 다양한 수령 또는 환경에 대한 자료를 수집하고 모형을 검증할 필요가 있다.
결 론
본 연구에서는 수피 기반 수목 동정에 활용될 수 있는 국내 수종의 수피 사진 자료를 구축하였다. 총 54개 수종에 대하여 7,000장 이상의 사진을 수집하여 공개하였고(DOI: 10.5281/zenodo.4749063), 향후 국내 수종의 수피 기반 동정 연구에 있어 매우 유용한 기초 자료가 될 것으로 기대된다. 이와 더불어, 본 연구와 선행 연구의 자료를 합쳐서 더 큰 분류 데이터셋을 만들고, 이를 CNN 모델을 통해 학습시킨 결과 90% 이상의 높은 정확도로 종을 식별할 수 있음을 확인하였다. 향후 잎과 꽃 등의 기관들을 함께 동정에 활용한다면, 실제 현장에 적용 가능할 정도의 높은 정확도를 얻을 수 있을 것으로 기대된다. 한편, CNN 모형은 약 2,000장 이상의 학습 자료를 가졌던 수종에 대해서 안정적인 분류가 가능하여 일정 수 이상의 개체 촬영 자료가 필요함을 알 수 있었다. 그리고 기존 학습자료에 포함시키지 않은 수종에 대해서는 대다수의 경우 같은 속 또는 과로 예측하는 것으로 확인하였다. 이를 통해 CNN 모델의 일반화 능력에 대한 가능성을 엿볼 수 있었으나, 더 많은 자료를 바탕으로 한 검증이 요구된다. 또한, 이끼와 만경 식물과 같이 수피에서 흔히 볼 수 있는 방해 요소가 분류의 정확도를 떨어뜨렸는데, 이러한 외적인 요소를 비롯하여, 환경 및 수령에 의해 나타나는 형질의 큰 변이 또한 수피 기반의 연구에서 반드시 극복해야 할 과제이다. 본 연구에서 제시하는 이러한 한계점들이 추가적인 자료 수집만으로 해결될 수 있는지, 혹은 기계 학습 모형의 개량 등 다른 측면의 질적 개선을 필요로 하는지 추후 연구에서 확인할 필요가 있다. 본 연구에서 구축한 자료와 도출된 결과들은 향후 자동 수목 인식 기술의 발전에 기여하고, 산림의 활용과 관련된 다양한 분야에서 유용하게 쓰일 것으로 기대된다.